일반적인 아키텍쳐

4가지의 계층으로 나누어져 어플리케이션을 구성한다.
표현 계층(UI)는 응용 계층을 위해 정보를 가공한다.
응용 계층은 도메인 계층을 가지고와 메소드를 호출한다.
응용 계층은 데이터의 저장을 위해 인프라스트럭쳐에 의존한다.
일반적으로 상위 계층이 하위 계층에 의존하는 구조를 가지고 있다.
이전 포스트에서 도메인 영역에서 도메인 핵심 규칙을 구현한다고 하였는데,
구현한 기능을 누가 사용하고 누가 관리할까?
바로 응용 계층이다.
스프링을 한참 공부하면서 Controller, Service, Repository 컴포넌트들의 역할을 무엇이고 왜 나누어져있는지 궁금했다.
맨땅에 박치기 방식으로 개발을 하다보니
Controller는 Service에서 사용할 데이터 가공,
Repository는 Service에서 사용할 데이터 로드,
Service는 비즈니스 로직 그 자체가 되었다.
각자의 역할을 분리해 서로의 의존성을 떨어뜨리는 목적으로 나누는것까지는 좋았는데,
문제는 Service가 너무 거대해졌다. 하나의 메소드만해도 여러 서비스의 메소드를 호출하고, 객체를 생성하고 가공하고
이런 작업들이 많아져 코드가 너무 복잡해졌었는데,
사실 Service 레이어는 비즈니스 로직을 포함하고 있으면 안되는 것이었다.
그럼 비즈니스 로직은 누가 처리하느냐? 바로 도메인에서 처리하면 된다.
Service 레이어는 그저 도메인 로직들의 실행 순서와 알맞은 메소드 호출만 담당해주면 된다는게 DDD의 관점이다.
코드로 보자
public class CancelOrderService{
@Transactional
public void cancelOrder(String orderId){
Order order = findOrderById(orderId);
if (order == null) throw new OrderNotFoundException(orderId);
order.cancel();
}
}
주문을 취소하는 서비스에서 직접 로직을 수행하지 않고, Order 도메인에게 로직 수행을 위임한다.
도메인 모델은 도메인의 핵심 로직을 구현한다.
DIP
Dependency Inversion Principle, 유명한 SOLID 5원칙 중 하나이다.
의존관계의 역전이라는 뜻인데, 구체 클래스에 의존하지 말고 추상화에 의존하게 만드는것이다.
위에서 상위 계층이 하위 계층에 의존한다고 했는데, 이를 뒤집어주는것이 DIP이다.
코드로 보자
public class CalculateDiscountService{
private SomeRepository someRepository;
private SomeDiscounter someDiscounter;
private Customer findCustomer(String customerId){
return someRepository.findById(customerId);
}
public Money calcualteDiscount(Order order, String customerId){
Customer customer = findCustomer(customerId);
return someDiscounter.applyRules(customer, order);
}
}
우리의 Service는 특정 Repository 구현체와 Discounter 구현체에 의존하고 있다.
구현체의 메소드 이름이 바뀌거나 파라미터 규약이 바뀌면 의존하고 있는 Service의 코드 변경도 일어날 수 밖에 없다.
하지만 본질만 보면 Service는 Discounter, Repository의 구현이 어떻게 되어있는지 관심을 안가져도 된다.
그냥 findById, applyRules라는 로직이 실행되는 타이밍만 정해주는것이다.
DIP는 해당 로직만을 가지게 추상화를하여 의존관계 역전을 하게 해준다.
public class CalculateDiscountService{
private IRepository iRepository;
private IDiscounter iDiscounter;
private Customer findCustomer(String customerId){
return iRepository.findById(customerId);
}
public Money calcualteDiscount(Order order, String customerId){
Customer customer = findCustomer(customerId);
return iDiscounter.applyRules(customer, order);
}
}
public interface IRepository{
public Customer findById(String customerId);
}
public interface IDiscounter{
public Money applyRules(Customer customer, Order order);
}
// Service 입장 : 아 몰라 나는 이런 로직 필요한 애들만 쓸거니까 너네가 알아서 구현해!!
더 이상 Service는 구현체에 의존하지 않고 추상화된 interface에 의존하게 된다.
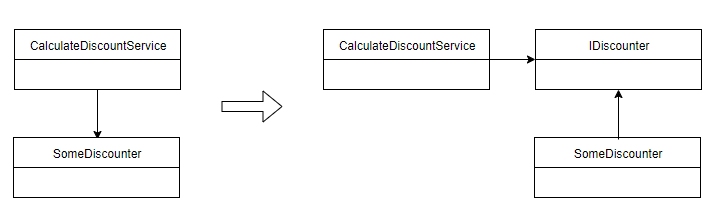
오히려 하위 계층들은 상위 계층의 interface에 의존한다.
이러면 DIP가 끝나게 되는데, 장점은 무엇일까?
우선 의존도가 전보다 떨어진다. 이를 Loose-Coupling이라고 하는데,
- 코드의 수정이 적어지게 된다. 구현체의 코드 변경은 구현체에서만 일어난다.
- 런타임에 구현체 갈아끼우기가 가능해진다. 구현체 변경이 쉬워진다.
- 확장성이 늘어난다. 새로운 discounter는 그저 인터페이스만 implement하면 된다.
- 테스트가 보다쉬워진다. 어떠한 discounter를 넣어도 테스트 코드는 변하지 않는다.
라는 장점이 있다!
도메인 영역의 주요 구성요소
| ENTITY | 고유의 식별자를 갖는 객체로 자신만의 라이프 사이클을 갖는다. 도메인 모델의 데이터를 포함하며 해당 데이터와 관련된 기능을 제공한다. |
| VALUE | 고유의 식별자를 갖지 않는 객체로, 개념적으로 하나인 값을 표현할 때 사용한다. 엔티티의 속성으로 사용될 수 있다. |
| AGGREGATE | 연관된 엔티티와 밸류 객체를 개념적으로 하나로 묶은것, Order 엔티티, OrderLine 밸류, Orderer 밸류 객체를 '주문' 이라는 애그리거트로 묶을 수 있다. |
| REPOSITORY | 도메인 모델의 영속성 처리 |
| DOMAIN SERVICE | 특정 엔티티에 속하지 않은 도메인 로직을 제공 ex) 할인 금액 계산은 상품, 쿠폰, 회원등급 등 여러 도메인을 이용한다. |
도메인 모델의 엔티티는 DB 관계형 모델의 엔티티와는 다르게, 데이터 뿐만아니라 기능도 포함하는 개념이다.
도메인 관점에서 기능을 구현하고 캡슐화 하여 데이터가 임의로 변경되는 것을 막는다.
예를 들어 주문을 표현하는 Order 엔티티는 주문과 관련된 데이터뿐만 아니라 배송지 주소 변경을 위한 기능을 함께 제공한다.
public class Order{
private OrderNo number;
private Orderer orderer;
private ShippingInfo shipppingInfo;
// 도메인 모델 엔티티는 도메인 기능도 함께 제공
public void changeShippingInfo(ShippingInfo shippingInfo){
checkShippingInfoChangeable();
setShippingInfo(newShippingInfo);
}
// private setter
private void setShippingInfo(ShippingInfo newShippingInfo){
if(newShippingInfo == null) throw new Exception();
// 밸류 타입의 데이터를 변경할 때는 아예 새로운 객체로 교체한다.(불변 유지)
this.shippingInfo = newShippingInfo;
}
}
도메인 모델의 엔티티는 단순히 데이터를 담고 있는 데이터 구조가 아닌 데이터와 함께, 기능을 제공하는 객체이다.
DB 관계형 모델의 엔티티와 또 다른점은, 도메인 모델의 엔티티는 밸류를 가질 수 있다는 점이다.
밸류는 개념적으로 하나인 값을 표현하는 객체로, 위의 예시에서는 Orderer 객체에 해당된다.
public class Orderer{
private String name;
private String email;
}
JPA는 연관관계를 지원하지만 별도의 설정이 필요하다. 하지만 도메인 모델 엔티티에서는 걱정할 필요가 없다.
애그리거트
도메인 모델이 복잡해지면 엔티티와 밸류가 자연스레 많아지게 되고 이를 관리할 더 큰 상위 개념이 필요하다.
애그리거트는 관련 객체를 하나로 묶은 군집이라고 할 수 있다.
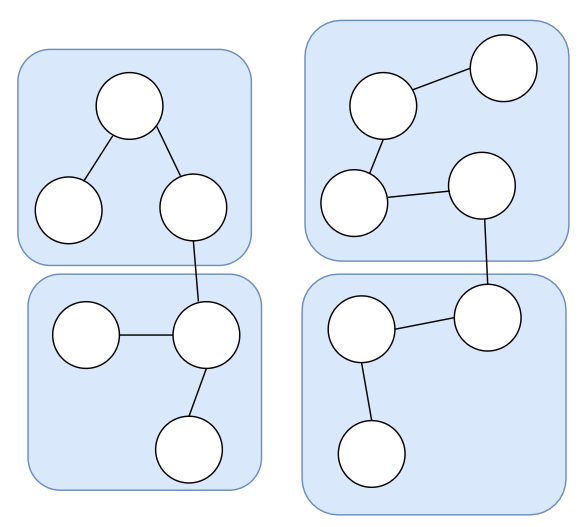
애그리거트를 사용하면 개별 객체가 아닌 관련 객체를 묶어서 객체 군집 단위로 모델을 바라볼 수 있게 된다.
개별 객체 간의 관계가 아닌 애그리거트 간의 관계로 도메인 모델을 이해할 수 있어 큰 틀에서 도메인 모델을 관리한다.
애그리거트는 군집에 속한 객체를 관리하는 루트 엔티티를 갖는다.
루트 엔티티는 애그리거트에 속해있는 엔티티와 밸류 객체를 이용해서 애그리거트가 구현해야 할 핵심 기능을 제공한다.
예를 들어 주문 애그리거트는 주문, 배송지 정보, 주문자, 주문 목록 엔티티들로 구성된다.
이때 주문 애그리거트의 루트 엔티티는 주문 엔티티이다.
애그리거트를 사용하는 코드는 애그리거트 루트 엔티티를 통해 간접적으로 애그리거트 내 다른 엔티티에 접근한다.
바꿔 말하면, 루트 엔티티를 거치지 않고서는 다른 애그리거트 내에 있는 엔티티에 접근을 하지 못한다는것이다.
이는 상호작용 하는 엔드포인트를 줄여 유지보수를 돕고, 보다 더 명확한 코드 사용을 보장한다.
'Back-End > DDD' 카테고리의 다른 글
| [DDD] 1. 도메인 모델 시작하기 (0) | 2023.03.31 |
|---|---|
| [DDD] 0. DDD 시작하기 (0) | 2023.03.31 |