Docker Swarm
지금까지의 도커 사용은 단일 호스트에서만 이루어졌다.
애플리케이션 규모가 작으면 상관 없겠지만 만약 규모가 더 늘어나게 된다면 어떻게 해야할까?
가장 먼저 떠오르는 생각은 서버의 성능을 높이자!(스케일 업) 이다.
현재 CPU가 듀얼코어에 메모리가 16GB니까,,,,, 새로운 쿼드코어 CPU와 32GB 메모리를 장착한다.
전보다 쾌적하게 서버가 운용되지만 이는 한계가 있다.
메모리와 CPU는 좋은 사양으로 갈수록 가격이 기하급수적으로 늘어나서 현실적인 해결방법이 아니다.
그 다음으로는 할 수 있는 조치가 뭐가 있을까?
단일 호스트가 아닌 여러 개의 서버를 만들자!(스케일 아웃) 이다.
기억하자. 우리는 컨테이너를 설계할 때 Stateless 하게 설계해왔기 때문에 스케일 아웃은 비교적 쉬울것이다.
근데 서버를 증설한다음 컨테이너를 똑같이 올리기만 하면 될까?
당연히 그 밑작업도 해주어야 할것이다.
로드밸런서도 붙이고 리커버리 플랜도 짜야하고 노드간의 통신도 지원해주어야 한다.
도커 스웜은 바로 이러한 설정을 해결해주는 도커에서 공식적으로 지원하는 오픈소스이다.
이렇게 컨테이너들을 각 노드에 배치해주고 관리하는 작업을 컨테이너 오케스트레이션이라고 하는데,
MSA 같이 확장성과 High Availability가 중요한 아키텍쳐에서는 필수이다.
사실 업계 표준은 도커 스웜이 아닌 쿠버네티스이다.
도커 스웜은 그렇게 자주 쓰이지 않지만 여러 가지 개념들이
쿠버네티스와 유사해서 알고 있으면 도움이 될 것 같아 이 포스트를 작성했다.
클러스터
클러스터는 여러 대의 서버를 하나의 자원 풀로 묶은 단위이다.
클러스터링은 물리적으로 분리되어있는 서버들을 논리적으로 하나의 자원 풀로 만드는 과정이다.
이러한 클러스터는 도커 스웜, k8s, kafka, spark, redis 등 여러 군데에서 사용된다.
이때 보통 하나의 서버를 노드라고 한다.
매니저 노드와 워커 노드
노드는 다시 크게 두 가지로 분류할 수 있는데,
매니저 노드와 워커 노드이다.
이름에서 알 수 있듯이 매니저 노드는 뭔가 매니징하는 여왕벌 같은 느낌이고
워커 노드는 열심히 일하는 일벌 느낌이다.
매니저 노드는 실제로 워커 노드들을 관리하는 서버이고,
워커 노드는 실제로 컨테이너가 생성되고 관리되는 서버이다.
물론 매니저 노드에서도 컨테이너가 생성될 수 있어 기본적으로 워커 노드의 역할을 포함하고 있다.
보통 클러스터는 최소 매니저 노드 1대, 워커 노드 3대로 총 노드가 4대 이상이 되도록 구성하고,
매니저 노드의 부하를 줄이거나 고가용성 등 안정적인 클러스터 운용을 위해서 매니저 노드를 여러 대 설정할 수도 있다.
환경마다 다르긴 하지만, 일반적으로 매니저 노드의 절반 이상에 장애가 생기면
클러스터에 가입된 Available한 워커 노드를 매니저 노드로 승격시켜
매니저 노드가 항상 과반수 이상, quorom 이상이 되도록 설정한다.
이때문에 매니저 노드는 가능한 홀수개로 구성하는 것이 좋다고 한다.
사실 매니저 노드중에서도 특별한 리더 노드 라는것이 하나 존재한다.
리더 노드는 모든 매니저 노드에 대한 데이터 동기화와 관리를 담당하고,
마찬가지로 리더 노드가 장애에 빠지면 새로운 매니저 노드가 리더 노드로 승격된다.
분산 코디네이터
매니저 노드와 워커 노드로 클러스터를 구축하고 나면,
매니저 노드가 다 알아서 노드들을 관리해주고 클러스터들을 관리해줄까?
환경마다 다른데, 분산 코디네이터를 따로 노드나 컨테이너로 두는 환경도 있다.
분산 코디네이터의 예시로는 etcd, zookeeper 등이 있으며
etcd는 쿠버네티스, zookeeper는 kafka를 운용하면서 써본 경험이 있다.
분산 코디네이터는 클러스터에 영입할 새로운 서버의 발견(Discovery), 클러스터 단위의 설정 저장, 데이터 동기화 등
여러 역할을 하며 안정적인 클러스터 운용을 도와준다.
도커 스웜은 3rd-party의 분산 코디네이터 보다는 매니저 노드에 내부 분산 코디네이터를 두어 이를 지원한다.
도커 스웜 클러스터 구축해보기
도커 스웜은 도커에서 공식적으로 지원하는 기능이고, 맨 처음 도커를 설치하게 되면 자동으로 설치가 된다.

ec2 : manager
ec2 : worker1
desktop : worker2
ec2 2대, desktop 1대, 총 3대로 도커 스웜 클러스터를 구축해보았다.
클러스터 생성
매니저 노드로 활용할 노드에서, 아래와 같은 명령어로 클러스터를 생성한다.
docker swarm init --advertise-addr [Public IP]
--advertise-addr 옵션에는 다른 노드에서 접근 가능한 해당 노드의 퍼블릭 IP를 적어준다.
명령어의 결과로 token을 알려주는데, 이는 다른 노드에서 방금 우리가 만든 클러스터에 가입할 때 필요한 토큰이다.
참고로 스웜 매니저는 기본적으로 2377번 포트를 사용하며,
노드 사이의 통신에 7946, ingress 오버레이 네트워크는 4789번 포트를 사용하므로
ec2를 이용해 도커 스웜 클러스터를 구축할 때 포트를 열어주어야 한다.
클러스터 가입
다른 ec2에서 방금 만든 클러스터에 토큰을 입력해서 가입해보자.
docker swarm join --token [Token] [Host IP:Port]
데스크탑에서도 똑같은 명령어로 가입하고 난 이후
매니저 노드에서 확인해보자.

모두 정상적으로 가입된 것을 확인할 수 있다.
토큰만 있으면 어디에 있는 컴퓨터든 가입할 수 있다!!
그래서 당연히 토큰은 탈취되면 안되고, 실무에서는 매시간마다 토큰을 바꾸는것으로 알고있다.
우리는 실습환경이니까 넘어가도록 하자.
도커 스웜 명령어
노드 목록 확인하기
docker node ls

현재 자신이 속한 클러스터에 있는 노드 목록을 보는 명령어로, 매니저 노드에서만 볼 수 있다.
클러스터에 매니저 추가하기
docker swarm join-token manager
클러스터에 매니저 노드를 더 추가하고 싶다면, 매니저 노드에서 위의 명령어를 통해
매니저 노드 추가만을 위한 토큰값을 확인할 수 있다.
이후 다른 노드에서 docker swarm join 명령어를 통해 매니저 노드 자격으로 클러스터 가입이 가능하다.
클러스터 탈퇴하기
docker swarm leave

매니저 노드는 기본적으로 leave를 할 수 없다.
--force 옵션을 통해 강제로 leave 할 수 있지만, 이렇게 되면 클러스터의 정보도 삭제되어
클러스터를 더 이상 사용하지 못하므로 조심해야 한다.
워커 노드에서 leave를 한다고 클러스터에서 완전히 삭제되는것이 아니다.

docker node rm 명령어를 통해 완전히 지워보자.

노드 승강
docker node promote [NODE]
docker node demote [NODE]매니저 노드는 워커 노드로, 워커 노드는 매니저 노드로 자격을 바꿀 수 있다.

luy 노드가 Reachable State로 바뀐것을 볼 수 있다.

다시 worker 노드로 강등시켰다.
도커 스웜 서비스
지금까지 우리가 도커, docker-compose를 통해 다루었던 제어 단위는 컨테이너들이다.
도커 스웜에서는 제어가 컨테이너가 아닌 서비스라는 새로운 단위로 이루어진다.
서비스
서비스는 같은 이미지에서 생성된 컨테이너의 집합이며,
서비스를 제어하면 해당 서비스 내의 컨테이너에 같은 명령이 수행된다.
서비스 내에 컨테이너는 1개 이상 존재할 수 있으며, 컨테이너들은 각 노드들에게 할당된다.
할당되는 컨테이너들을 레플리카셋이라고 하는데, 그림으로 나타내면 다음과 같다.
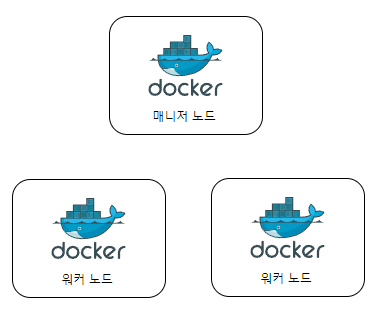
베이스 이미지로 서비스를 생성하고, 레플리카셋을 3으로 설정한 그림이다.
각 노드에 컨테이너를 할당해주는것은 누가 할까? 스웜 스케쥴러라는 친구가 해준다.
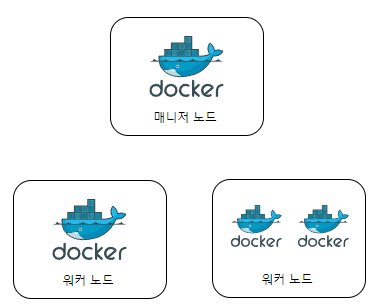
만약 레플리카셋이 3이 아닌 4 라면?
스케쥴러에 의해서 어느 노드는 두 개의 컨테이너를 가지고 있을것이다.
만약 레플리카셋이 3인데 특정 노드가 다운된다면?
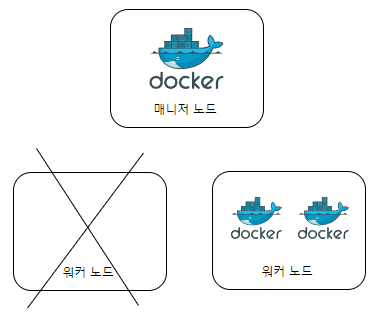
이 모든 동작은 스웜 스케쥴러가 담당한다.
그리고 서비스를 제어하는 도커 명령어는 전부 매니저 노드에서만 사용할 수 있다.
서비스 생성
실제로 서비스 생성을 해보자.
가장 만만한 nginx 웹 서버를 만들어 보자.
docker service create --name myweb --replicas 2 -p 80:80 nginx
뭔가 된거같은데 확인은 어떻게 해야할까?
docker service ls
2개의 컨테이너가 만들어진것을 확인할 수 있다.
docker service ps myweb
worker 1과 worker 2에서 curl localhost:80 으로 요청을 보내면 잘 되는것을 확인할 수 있다.
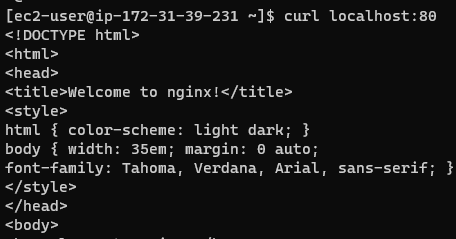
또한 docker ps 명령어로, 스웜 스케쥴러가 만든 컨테이너를 확인할 수 있다.

서비스의 비밀
그런데, manager 노드에서는 어떨까?
컨테이너는 당연히 생성이 안되었으니 curl 명령이 안먹을 것이다.
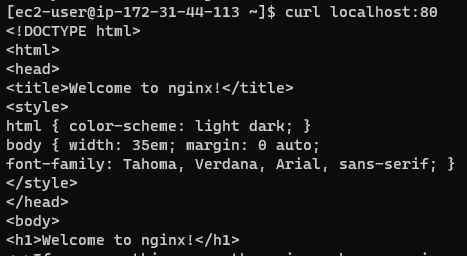
분명 매니저 노드에는 nginx 컨테이너가 생성되지 않았는데 nginx welcome 화면이 나온다.
어떻게 된 일일까?
결론부터 말하자면, 우리가 보낸 요청은 컨테이너가 처리하긴 하지만,
스웜 모드 서비스가 먼저 해당 요청을 보고 클러스터에 속한 노드들에게
Round Robin 방식으로 리다이렉트 하는 방식이다.
따라서 특정 노드의 IP 주소로 접근해도, 스케쥴링 알고리즘에 의해 다른 노드에 속한 컨테이너가
해당 요청을 처리하게 된다. 이를통해 자유롭게 스케일을 조정할 수 있다.
서비스 스케일 아웃
서비스의 레플리카셋을 조정할 수 있다.
docker service scale myweb=4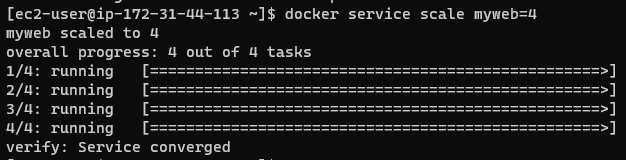

매니저 노드에 2개의 컨테이너가 할당된것을 볼 수 있다.
Secret과 Config
애플리케이션을 외부에 서비스 하려면 각종 설정 파일과 비밀번호, 키가 필요하다.
그런데 우리는 분산 클러스터 환경으로 애플리케이션을 만들었고,
모든 노드는 이 정보가 필요하다. 어떻게 해야 할까?
일차적으로 드는 생각은 모든 노드에 파일을 저장하는것인데,
이는 보안 관점에서도 안좋고 변경사항을 추적하기 힘들다.
도커 스웜은 이를 Secret 과 Config라는 기능을 제공해 해결한다.
이는 쿠버네티스에서도 똑같이 제공하며 자세한 내용은 쿠버네티스 포스트에서 다루겠다.
도커 스웜 네트워크
도커 스웜은 클러스터를 구성해서 각 노드에게 컨테이너를 할당하기 때문에
각 도커 데몬의 네트워크가 하나로 묶인 네트워크 풀이 필요하다.
이뿐만 아니라 서비스를 외부로 노출했을 때 위의 예시에서처럼 어느 노드로 접근하더라도
해당 서비스의 컨테이너에 접근할 수 있게 해주는 라우팅 기능도 필요하다.
이전까지는 일반적인 도커 컨테이너에서 host 네트워크, docker-compose에서 bridge 네트워크만을 사용했었는데,
도커 스웜에서는 또 다른 네트워크가 등장한다.
ingress 네트워크
ingress 네트워크는 클러스터를 생성하면 자동으로 등록되는 네트워크로서, 구조는 다음과 같다.
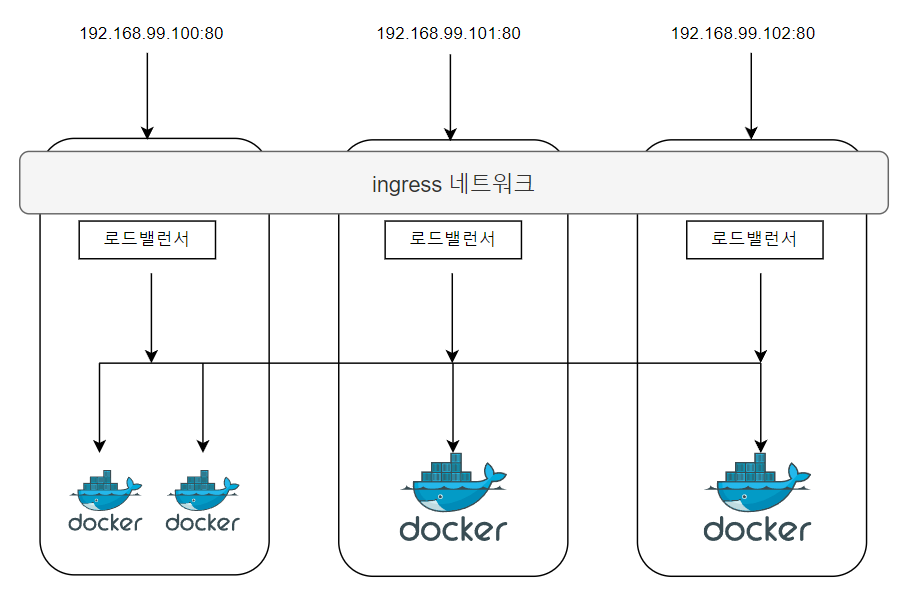
ingress 네트워크는 어떤 스웜 노드에 접근하더라도 서비스 내의 컨테이너에 접근할 수 있게 라우팅 메시를 구성하며
서비스 내의 컨테이너에 대한 접근을 Round Robin 방식으로 제공하는 로드 밸런싱을 담당한다.
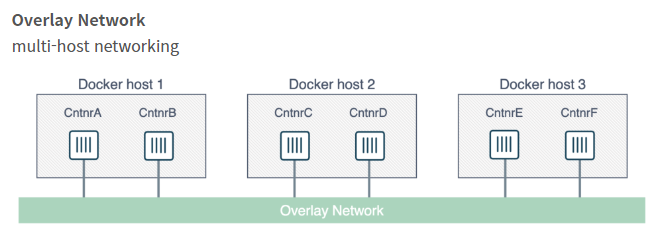
overlay 네트워크
overlay 네트워크는 스웜 클러스터 내의 컨테이너에게 할당하는 IP를 관리하고
그들간의 통신을 할 수 있게 만들어준다.
서비스 디스커버리
도커 스웜을 사용하면, 컨테이너의 생성과 삭제가 빈번하다.
그렇다면 새롭게 생성된 컨테이너에 어떻게 접근할 수 있을까?
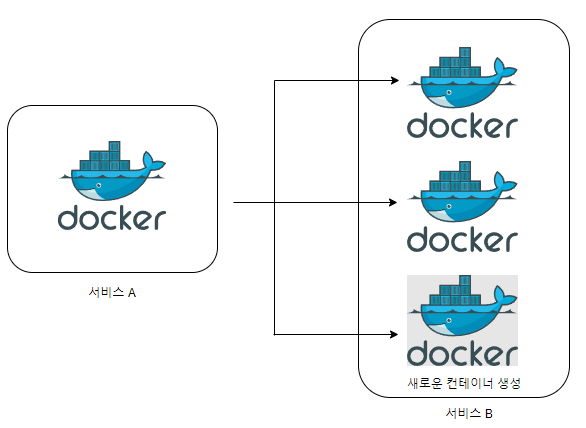
위에서 얘기했던 것 처럼, 도커 스웜에서는 컨테이너와 직접적으로 통신하는것이 아닌
서비스 단위로 통신하기 때문에 서비스 A는 서비스 B에서 새롭게 생성된 컨테이너의 IP를 알 필요 없이
서비스 B의 이름만 알고 요청을 전달하면 된다!
'Infra > Docker' 카테고리의 다른 글
| [Docker] Docker Compose (0) | 2023.06.27 |
|---|---|
| [Docker] Docker Daemon (0) | 2023.06.27 |
| [Docker] Dockerfile (1) | 2023.05.20 |
| [Docker] 도커 볼륨과 네트워크 (0) | 2023.05.19 |
| [Docker] 도커 이미지와 컨테이너 (0) | 2023.05.18 |